
GPT-5.4发布:OpenAI首个大一统模型,简直是龙虾原生
2026-03-06 12:49:01 量子位 产品
GPT-5.4,它来了!
它更像是一个“模型能力大一统”成果:OpenAI首次在单一模型中,把推理(Reasoning)、编程(Coding)、计算机原生交互(Computer Use)、深度网页搜索以及百万级Token上下文全部揉碎、重组,焊死在了同一个模型里。
重点是,没有因为N in one而牺牲掉任何一个单项的性能——
OpenAI特别强调,GPT-5.4在以上领域的多个关键基准测试中依然保持领先。
跳票许久的OpenAI,终于冷不丁给了AI大模型圈梆梆一拳。
其中最能吸引开发者目光的,莫过于它是OpenAI首个原生支持“计算机使用”能力的通用模型。
我耳边都已经听到GPT-5.4的声音了:
玩儿龙虾的朋友们,走过路过考虑一下我咯~

同时,官方博文显示,GPT-5.4的效率也出现了明显提升。
相比GPT-5.2,GPT-5.4在推理过程中使用的Token数量显著减少。
Token消耗下降意味着响应速度更快,同时整体成本也更低。
是的,它变强了,但也变便宜、变快了。
这也是OpenAI这次发布反复强调的一点:能力提升和效率优化是同时发生的。

随着GPT-5.4上线,ChatGPT中的模型体系也随之调整。
GPT-5.4同步上线ChatGPT、API以及Codex。
在API价格体系中,GPT-5.4的单Token价格略高于GPT-5.2,但由于任务所需Token减少,总体成本可能并不会上升太多。
面向复杂任务的GPT-5.4 Pro版本也一起推出,在ChatGPT中则提供为GPT-5.4 Thinking。
值得小伙伴们注意的一点,GPT-5.4 Thinking将取代此前的GPT-5.2 Thinking,且GPT-5.2将在三个月后正式退役。
而GPT-5.1系列将在3月11日就要从ChatGPT里say bye bye了。
珍惜你们最后相处的甜蜜时光吧~
目前各个社交媒体已经炸开了锅。
有网友感慨道拥有百万token上下文窗口、还能原生使用电脑的GPT-5.4,和苹果史上最便宜笔记本电脑MacBook Neo同周发布……
“天爷啊,我的笔记本电脑正在经历一场存在主义危机!!”
三大能力提升,系OpenAI首个原生支持电脑操作的通用模型
在具体能力层面,GPT-5.4的升级可以概括为三个方向:
深度知识工作 (Knowledge Work)
原生计算机使用 (Computer Use)
高阶编程与调试 (Coding)
这三种能力基本覆盖了当前大多数数字工作的核心流程,而GPT-5.4都做得挺出色。
我们一一来看。
深度知识工作 (Knowledge Work)
首先是知识工作能力。
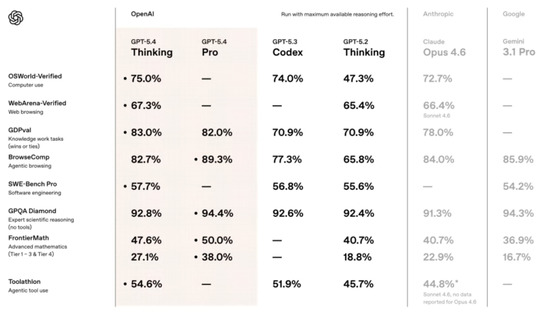
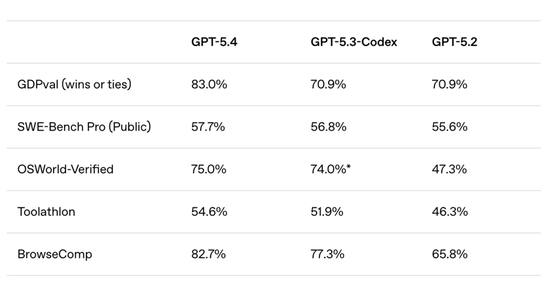
在衡量AI处理44种职业知识工作能力的GDPval基准测试中,它平局+获胜的综合得分83.0%。
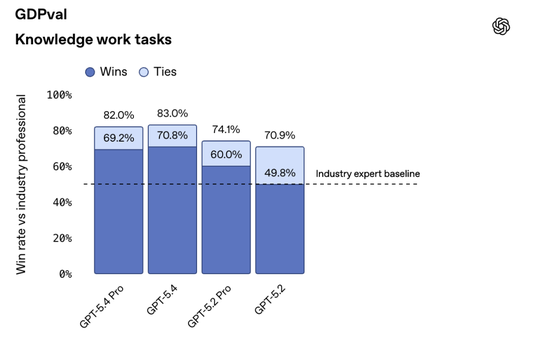
多说几句嗷,GDPval评测主要是用来测试模型在真实职业场景中的表现,它评测涉及44种职业,覆盖了美国GDP贡献最高的9个行业。
具体任务上并不只是简单问答,它要求模型完成真实工作产物,例如销售演示文稿、会计表格、排班表、制造流程图甚至短视频。
所以在大量知识工作任务中,GPT-5.4的结果已经能够与专业从业者持平,甚至超过他们。
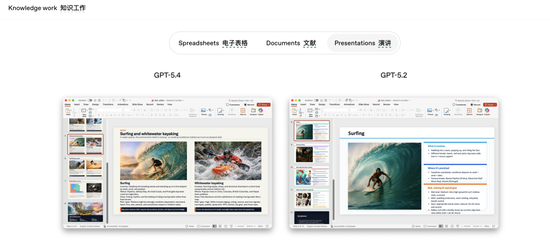
此外,OpenAI特别强化了GPT-5.4在办公文档领域的能力。
例如在内部投资银行建模测试中,GPT-5.4的平均得分达到87.3%,而GPT-5.2为68.4%。在人类评审的PPT生成测试中,评委有68%的时间更偏好GPT-5.4生成的结果,原因包括视觉效果更好、版式更丰富以及图片使用更合理。
从应用角度来看,这些能力对应的场景非常直接。
包括写报告、做财务模型、制作演示文稿、分析商业数据等工作,都是典型的知识型任务。
GPT-5.4正在朝着这类任务进行专门优化。
原生计算机使用 (Computer Use)
GPT-5.4最引人关注的一项能力是原生计算机操作,这是GPT-5.4区别于以往所有模型的核心标志。
模型可以通过截图理解软件界面,然后执行鼠标点击和键盘输入等操作。
包括发送邮件、创建日历事件、填写表单、操作网页等……都可以通过这种方式完成。
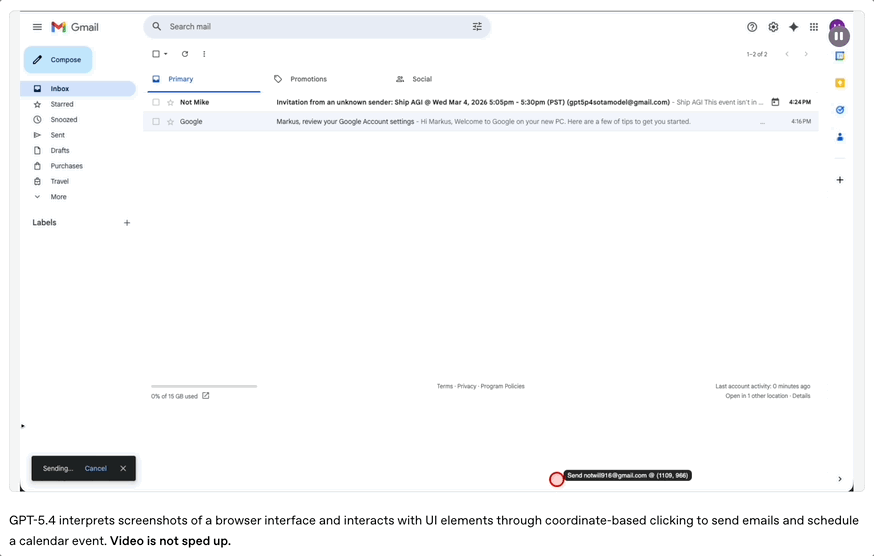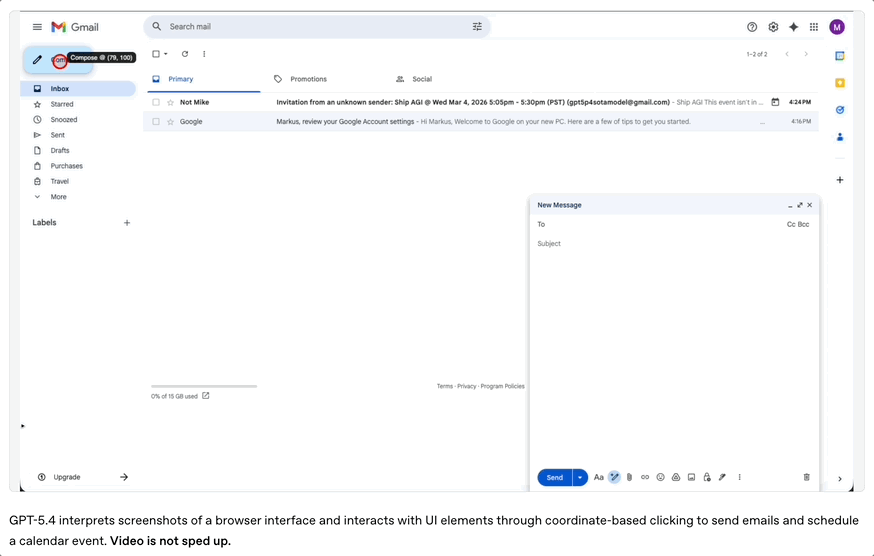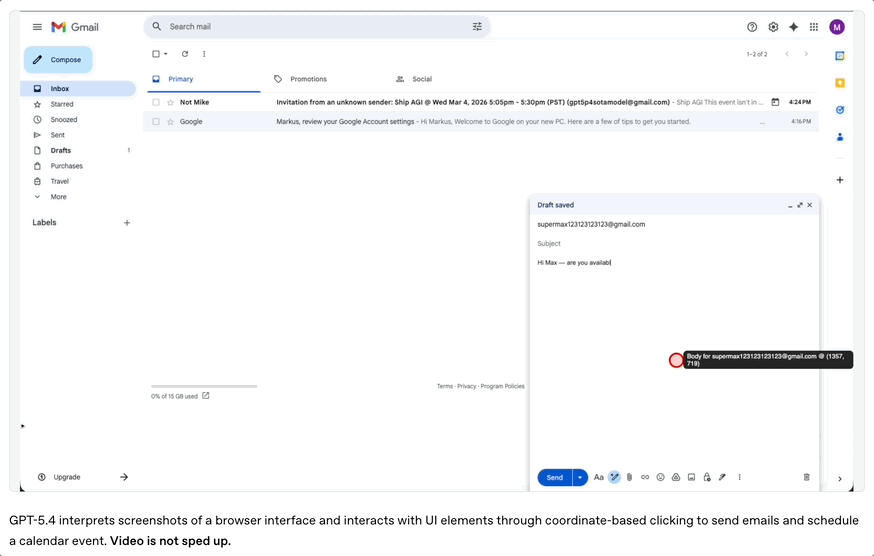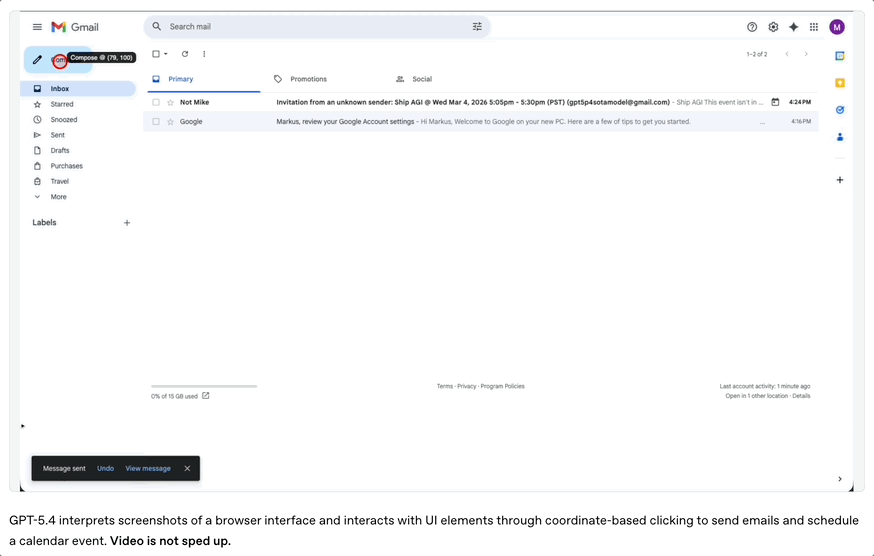
在WebArena浏览器任务测试中,GPT-5.4取得67.3%的成功率,高于GPT-5.2的65.4%。
在Online-Mind2Web测试中,仅通过截图观察完成网页操作时,GPT-5.4的成功率达到92.8%。
此外,在OSWorld-Verified基准测试中,GPT-5.4在桌面操作任务中的成功率达到75.0%,已经超过人类平均水平(72.4%)。
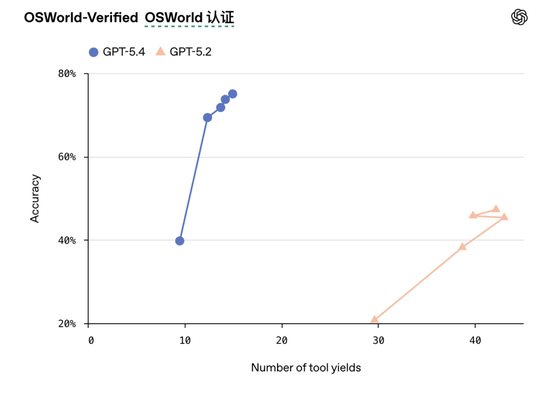
这些数据背后代表的是一种新的交互模式,也算是没落下最近的龙虾狂热潮。
高阶编程与调试
第三个关键能力来自编程。
而且强调的是“高阶编程”。
GPT-5.4吸纳了此前最强的编程模型GPT-5.3-Codex的能力。现在的它不仅支持Token输出速度提升1.5倍的/fast模式,还加入了一个名为“Playwright (Interactive)”的实验性技能。
它允许AI在帮你写网页或者应用时,开启一个窗口进行视觉化调试。
比如你给它一个简单的需求去做模拟游戏,它能一边生成美术资产、一边写逻辑,甚至一边运行自动测试来验证游戏状态是否正常。
在SWE-Bench Pro测试中,GPT-5.4取得57.7%的成绩,略高于GPT-5.3-Codex的56.8%,同时延迟更低。
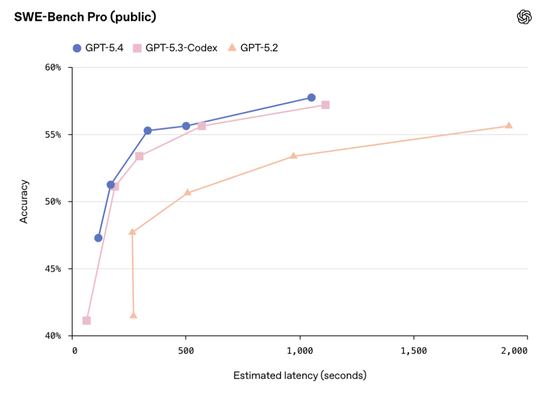
内部测试还显示,GPT-5.4在复杂前端任务中的表现明显优于此前模型。生成的界面设计更加美观,功能结构也更完整。
为了展示这一能力,OpenAI演示了一个由GPT-5.4生成的浏览器主题公园模拟游戏。
模型从简单提示词出发,生成游戏资源、构建场景、编写逻辑,并通过自动浏览器测试不断迭代。
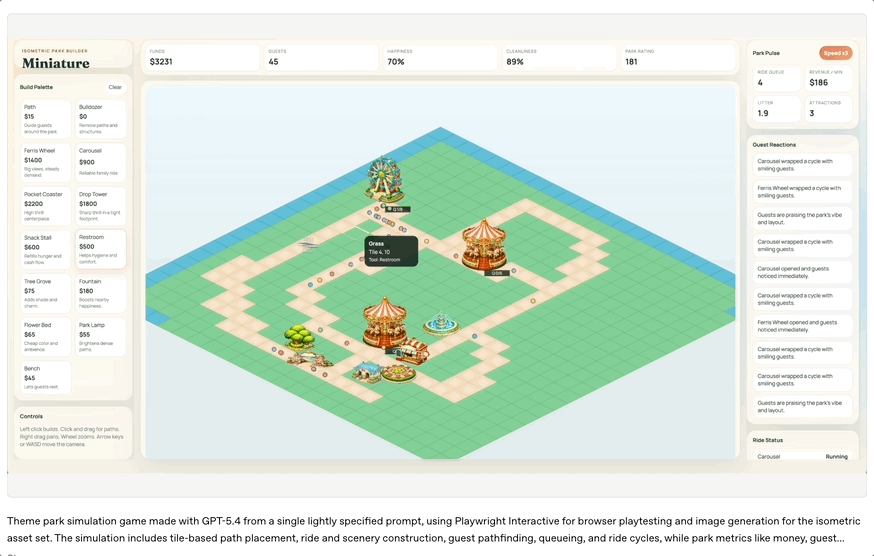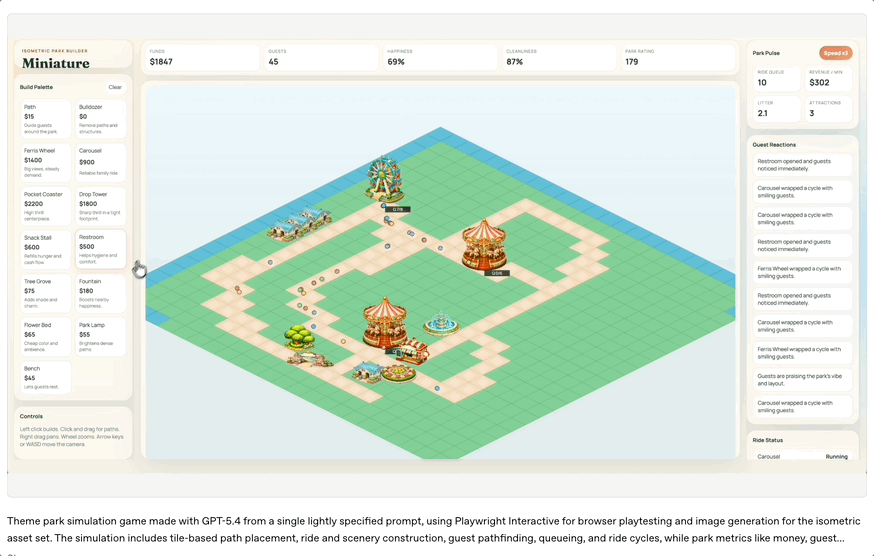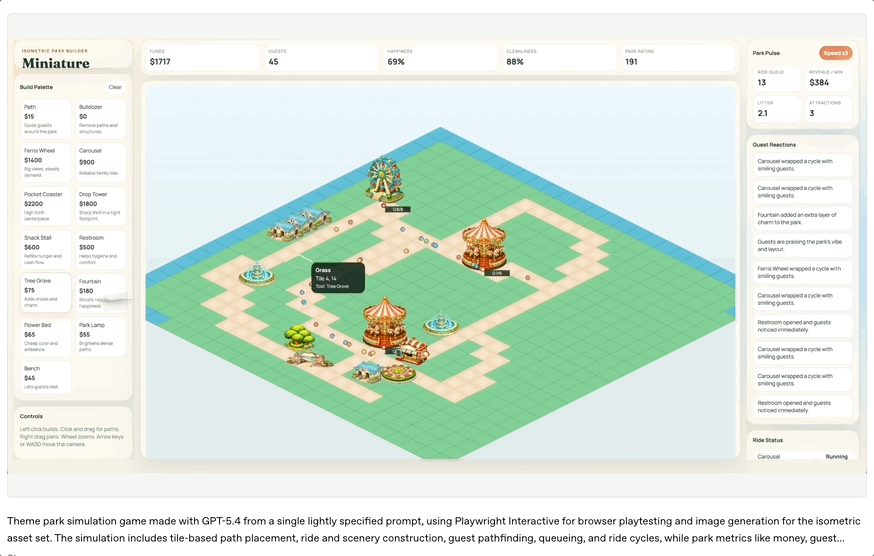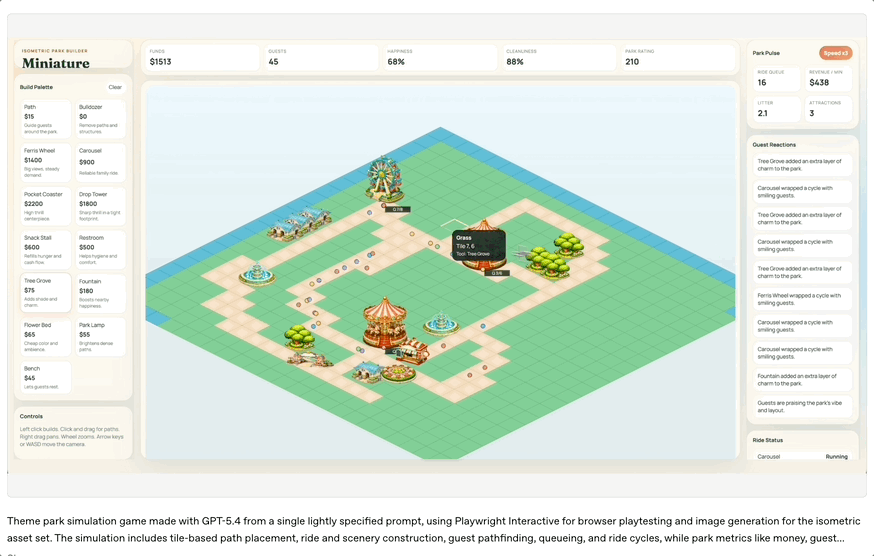
这种“边造边测”的能力,已经非常接近一个人类高级全栈工程师的工作流。
一种趋势不言而喻:
UI交互正在取代繁琐的API对接,成为AI操作世界的新主流路径。
emmmm,这可能会让很多中间件失去价值。
整体定位:AI数字员工
看完上述能力的整合,你就能读懂OpenAI在官方博文里透露出的野心。
OpenAI在发布文章中多次提到:
GPT-5.4的目标是成为能够完成真实工作的Agent系统。
如果说之前的GPT模型版本还是一个需要你盯着看的辅助工具,那么GPT-5.4已经开始尝试成为一个能独立负责整块业务的数字员工。
这种“AI数字员工化”体现在三个维度的飞跃。
首先是电脑操作能力。
模型可以通过截图理解软件界面,并通过鼠标和键盘指令进行操作。
这使得AI能够直接在电脑环境中执行任务。
其次是浏览器任务能力。
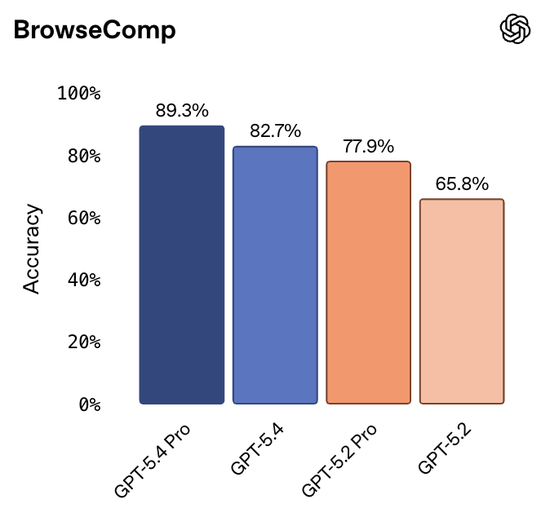
在BrowseComp测试中,GPT-5.4的成绩达到82.7%,而GPT-5.4 Pro达到89.3%,比GPT-5.2提升17个百分点。
这意味着模型能够持续搜索网页、筛选信息并整合结果,尤其适合处理需要多轮检索的问题。
第三是多工具调用能力。
在Toolathlon基准测试中,GPT-5.4取得54.6%的准确率,高于GPT-5.2的45.7%。
这个测试的任务通常需要多步骤操作,例如读取邮件附件、上传文件、评分作业并记录到表格中。
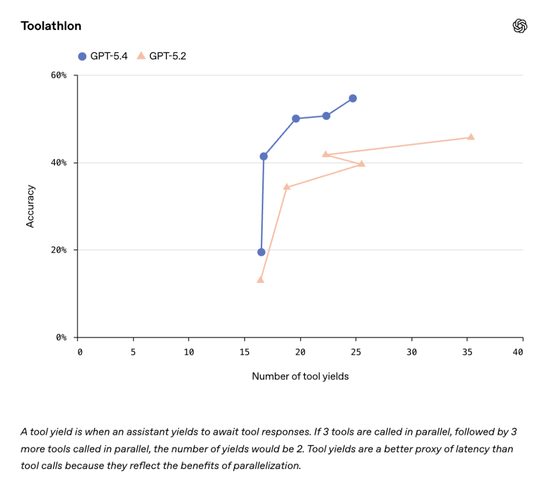
这种按需检索工具的能力是降低Agent运行成本的关键,它解决了过去模型在面对复杂指令时容易“迷路”或者Token爆炸的问题。
此外,对于对延迟要求较高的场景(在这种场景中,人们倾向于不进行推理操作),GPT-5.4 比其前辈版本有了进一步的改进。
细节之处的全面进化
除了上述支柱能力,GPT-5.4在办公细节上也进行了大量打磨。
比如它在创建和编辑电子表格、PPT方面的表现,其表格建模准确率从68.4%跃升至87.3%。
在演示文稿生成测试中,人类评审也更偏好GPT-5.4的结果,认为其视觉多样性和审美更强。
同时,视觉能力的提升也带动了文档解析的进步。
在MMMU-Pro视觉推理测试中,GPT-5.4取得81.2%的准确率,高于GPT-5.2的79.5%。
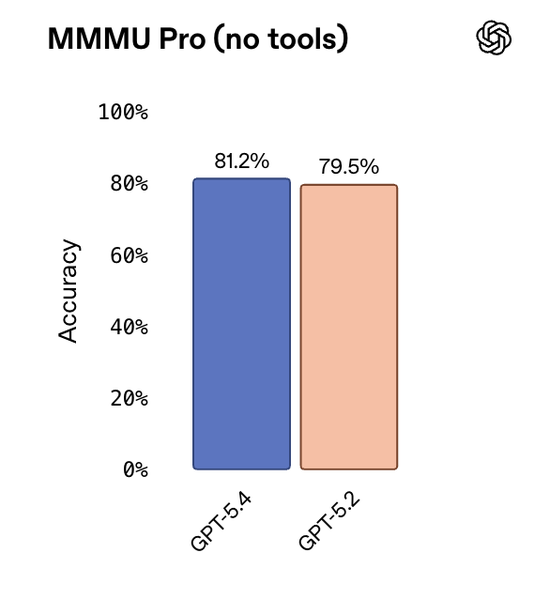
更重要的是,它现在支持高达1024万像素的原图输入,对高密度、高分辨率的图像理解更加精准。
视觉能力的提升也带来了更强的文档解析能力。
在OmniDocBench测试中,GPT-5.4的平均错误率从0.140下降到0.109。
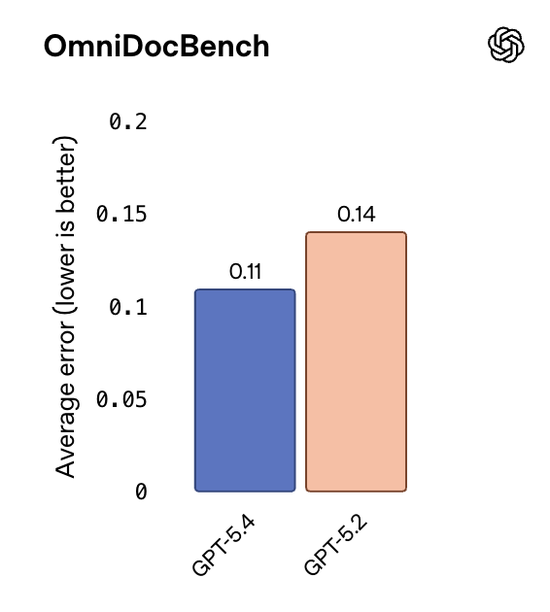
最令人欣慰的是错误率的下降。
从官方介绍中能初步感觉到,GPT-5.4是个极其讲求事实的模型,其事实错误概率比前代降低了33%,大大缓解了用户对模型幻觉的焦虑。

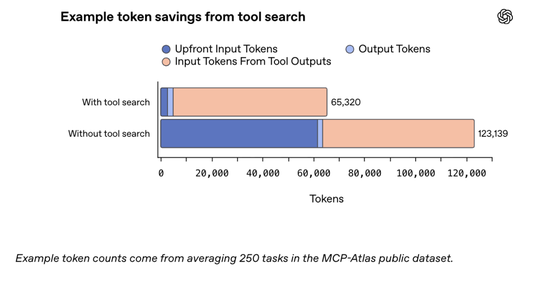
在效率方面,GPT-5.4引入工具搜索机制。
过去模型在使用工具时,需要在Prompt中包含所有工具定义。如果工具数量很多,Prompt就会变得非常庞大。
现在模型可以先获取工具列表,然后按需查询具体工具定义。
在实现相同准确率的情况下,将总Token使用率降低了47%。
这种成本控制手段说明OpenAI正试图让大模型大规模商业化变得更加现实,毕竟对于企业来说,省钱和好用同等重要。
更好用了,但更省钱了吗?
从OpenAI公布的API定价表来看,GPT-5.4的定价确实比5.2版本要高出一截。
GPT-5.2的每百万Token输入/输出价格分别是1.75美元和14美元,而GPT-5.4则上涨到了2.5美元和15美元。
尤其是对于那些追求极限性能的用户,GPT-5.4 Pro的价格更是飙升到了每百万输入30美元。
当然,原因肯定是5.4被定位为针对专业机构和高端生产力场景的溢价产品。
如果你只是写写简单的闲聊文案,继续用5.2其实更划算。

不过虽然单价涨了,但GPT-5.4在Agent任务中的“省钱之道”主要藏在它的技术机制里。
最核心的一点是就是工具搜索(Tool Search)功能。
以往我们让AI接入外部工具(比如接入几十个公司的数据库和内部接口)时,必须把所有工具的定义全部塞进提示词里。
哪怕AI这次只用了一个工具,你也得为剩下的几十个工具的定义支付Token费用。
但在GPT-5.4下,由于引入了类似“查字典”的搜索机制,模型可以先看一遍简略的工具清单,等确定要用哪个时,再临时去调取那个工具的详细定义。
在针对MCP Atlas基准测试的实验中,这项技术在保持同等准确率的情况下,把总Token使用量足足降低了47%。
One more Thing
大家沉浸在技术狂欢中时,也有网友分享了一些肉痛瞬间。
永远在冲浪一线的Yuchen Jin只是对GPT 5.4 Pro说了一句“Hi,俺是Anthropic创始人”,就花掉了整整560元……
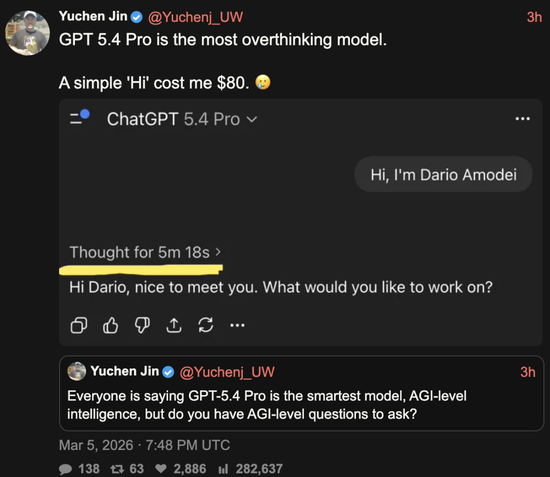
技术进步好快,但网友的心好痛。
这也引出一个问题,杀鸡焉用牛刀?
如果GPT-5.4 Pro是最智能、最接近AGI的模型……那么,你有什么AGI级别的问题要问它呢?
(何况还这么贵,TAT)


